Danh mục dự án
Bên cạnh Sora của OpenAI đang gây sốt toàn cầu, nhiều mô hình AI khác tạo video từ văn bản cũng được đánh giá cao như Lumier, VideoPoet, Emu Video.
Sora
Sora là sản phẩm mới được ra mắt cách đây vài ngày bởi OpenAI – công ty tạo ra ChatGPT. Với sự nổi tiếng của công ty mẹ và khả năng “thấu hiểu sâu sắc ngôn ngữ” của mô hình, nhiều người dùng tỏ ra hào hứng với Sora. Các video minh họa có thể thấy mô hình AI này tạo ra “những nhân vật có khả năng thể hiện cảm xúc sinh động”, theo Analyticsindiamag.

Lumier
Lumiere dựa trên mô hình khuếch tán có tên Sapce-Time-U-Net. Theo Ars Technica, Lumiere tìm cách ghép các khung hình tĩnh lại với nhau, thay vào đó, AI này tìm các chi tiết trong video (không gian) và theo dõi cách chúng di chuyển và thay đổi cùng một lúc (thời gian).
Hiện Lumiere chưa đưa ra công chúng nhưng Google có khả năng phát triển những mô hình AI vượt trội hơn các công cụ hiện tại như Runway hay Pika. Trên thực tế, chỉ trong hai năm, hãng đã có bước nhảy vọt về công nghệ trong lĩnh vực video game có AI.

VideoPoet
VideoPoet là một mô hình ngôn ngữ lớn (LLM) được đào tạo từ kho lưu trữ video, hình ảnh, âm thanh và văn bản khổng lồ. Công cụ này có thể thực hiện nhiều tác vụ tạo video khác nhau từ các nguồn đầu vào như văn bản, ảnh, video, làm nổi bật video theo phong cách, nội dung… hay chuyển đổi video thành âm thanh.
Công cụ này được xây dựng từ một ý tưởng rất đơn giản: chuyển đổi bất kỳ mô hình ngôn ngữ tự hồi quy nào được nhập vào thành hệ thống tạo video. Hiện tại, các mô hình ngôn ngữ tự hồi quy có thể xử lý văn bản và mã hoàn toàn tự nhiên nhưng gặp phải trở ngại khi chuyển sang video. Để giải quyết vấn đề này, VideoPoet sử dụng mã thông báo có thể chuyển đổi video, ảnh, âm thanh… sang ngôn ngữ mà nó có thể hiểu được.
Emu Video
Một công ty công nghệ lớn khác là Meta cũng có mô hình AI làm video riêng có tên Emu Video. Công cụ này hoạt động theo 2 bước: đầu tiên sẽ chuyển hình ảnh thành văn bản, sau đó sử dụng văn bản và hình ảnh để tạo video.
Những đánh giá viên tham gia chương trình này cho biết 81% trong số họ ưa thích Emu Video hơn Imagen Video của Google, 90% chọn công cụ này thay vì PYOCO (Nvidia) và có đến 96% đánh giá nó tốt hơn Make-A -Meta.

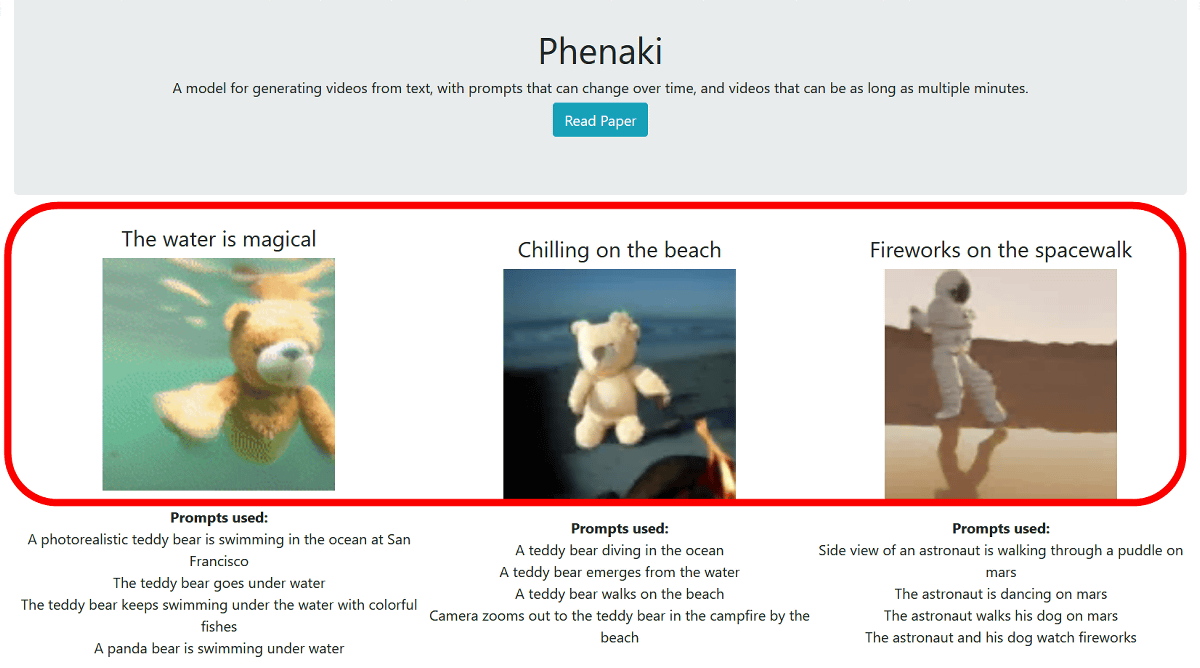
Phenaki
Nhóm phát triển Phenaki Video sử dụng Mask GIT để sản xuất video từ văn bản trong PyTorch – khuôn khổ máy học dựa trên thư viện Torchh, được sử dụng trong lĩnh vực thị giác máy tính và xử lý ngôn ngữ tự nhiên do Meta AI phát triển. Mô hình này sử dụng văn bản để tạo video có thời lượng tối đa hai phút.
Mô hình này được đánh giá là linh hoạt và khả dụng để các nhà phát triển đào tạo AI chuyển đổi văn bản thành ảnh hoặc video. Họ có thể bắt đầu bằng hình ảnh và sau đó tinh chỉnh chúng thành video mà không gặp bất kỳ trở ngại nào.
CogVideo
Một nhóm các nhà nghiên cứu từ Đại học Thanh Hoa (Bắc Kinh, Trung Quốc) đã phát triển CogVideo, một mô hình AI tạo sinh chuyển đổi văn bản thành video trên quy mô lớn. Họ đã xây dựng CogVideo từ mô hình chuyển văn bản thành hình ảnh có tên là CogView2 để khám phá những kiến thức nà công cụ này đã học được.
Nghệ sĩ Glenn Marshall đã rất ấn tượng khi thử nghiệm mô hình này đến nỗi ông cho rằng các đạo diễn có thể mất việc. Đoạn video The Crow được ông tạo bằng CogVideo cũng được đánh giá rất cao, thậm chí còn được tham dự giải thưởng Điện ảnh Viện Hàn lâm Anh (BAFTA).

Trên đây là một số mô hình AI tạo video từ văn bản mà các marketer cần biết. Các mô hình này đều có khả năng tạo ra video chất lượng và đa dạng từ các đoạn văn bản, giúp tiết kiệm thời gian và tài nguyên cho các doanh nghiệp. Hãy thử nghiệm và tìm hiểu thêm về các mô hình này để tận dụng tối đa tiềm năng của video trong chiến lược marketing của bạn.















{kind=link}